The price of invisibility
How a lack of Observability leads to downtime and reputational damage
How a lack of Observability leads to downtime and reputational damage
As infrastructures scale to keep pace with business demands, missing out on advanced monitoring and observability practices can lead to significant operational disruptions and, more damagingly, reputational damage.
Here we look at two fairly recent and high-profile examples from 2022 and 2023 where the lack of observability contributed to severe downtime and brand damage.
In October 2022, Meta (formerly Facebook) faced a significant outage that impacted billions of users worldwide. Platforms such as Facebook, Instagram, WhatsApp, and Messenger were down for hours, affecting both personal and business activities across the globe. This massive outage occurred during a period when Meta was already facing intense scrutiny over privacy and other internal issues.
The cause of the outage was later identified as a network configuration change that disrupted Meta’s backbone infrastructure. However, what made this incident particularly concerning was the company’s response. Due to a lack of visibility into the system’s real-time health, Meta’s engineers were unable to quickly pinpoint the root cause of the disruption. The company’s monitoring tools, while extensive, failed to provide the right visibility into the intricacies of its complex, interdependent network infrastructure.
The prolonged downtime, lasting several hours, caused widespread frustration, especially for businesses that rely on these platforms for marketing, customer service, and sales. Small businesses, in particular, found themselves at a standstill, unable to manage their digital presence or interact with customers. The reputational damage to Meta was substantial. Once again, users and businesses questioned the company’s ability to manage its infrastructure at the scale required by billions of active users. Meta’s failure to quickly address the problem led to widespread criticism, especially from advertisers who rely heavily on the platform for their campaigns.
Had Meta employed more robust observability solutions that could offer proactive, real-time insights into network performance and system dependencies, the issue could have been detected much earlier, and the recovery time could have been minimised. Instead, the outage exposed cracks in Meta's infrastructure and its ability to manage large-scale outages promptly, so diminishing user trust and corporate credibility.

In 2023, T-Mobile experienced a significant service outage that affected thousands of its customers across the United States. The outage was tied to failures in the company’s billing and customer support systems, resulting in customers being unable to access their accounts or make changes to their plans. For a telecommunications company, where real-time access to customer accounts is essential, this was a major disruption.
The issue stemmed from a bug introduced in an update to the billing system, which was not immediately detected due to a lack of proper observability tools. While T-Mobile had monitoring in place, it didn’t provide the granular visibility needed to understand how the bug was impacting the interconnected customer service systems. As a result, the outage persisted for several hours, and customers were left unable to resolve issues such as paying bills or managing their accounts.
The outage had immediate operational consequences, as T-Mobile’s customer service teams were overwhelmed by the volume of calls from frustrated customers. But the reputational damage was more severe. For a company like T-Mobile, which prides itself on customer experience and has a history of dealing with outages, this event caused significant trust erosion. The lack of effective monitoring and observability meant that T-Mobile’s response was slower than expected, leaving customers feeling unheard and frustrated.
Had T-Mobile implemented a more effective observability framework, it could have pinpointed the issue earlier, allowing for quicker resolution and better communication with customers. Observability would have provided real-time insights into the health of the company’s billing and customer service systems, allowing T-Mobile to identify and address the problem before it escalated into a full-blown outage.
Both the Meta and T-Mobile outages demonstrate the severe consequences of lacking comprehensive observability tools. In both cases, businesses were unable to detect and resolve issues in real-time, which led to extended downtime and considerable reputational damage. These incidents are reminders for businesses large and small that they cannot afford to overlook observability as a strategic priority.
Real-time monitoring and observability provide businesses with critical insights into the health and performance of their systems. Without these tools, companies are left reacting to problems after they occur, which can cause significant operational disruptions and hurt customer trust.
In today’s world, where customers expect seamless, uninterrupted service, businesses must invest in observability solutions that offer proactive monitoring, early detection of anomalies, and quick responses to potential problems. As the Meta and T-Mobile examples show, the risks of ignoring observability are too great, leading not only to downtime but also to long-term damage to customer loyalty and brand reputation.
Elastic Observability allows you to unify visibility across your entire AWS and on premises environments, enabling better insights into the performance and overall health of your infrastructure, applications, and business.
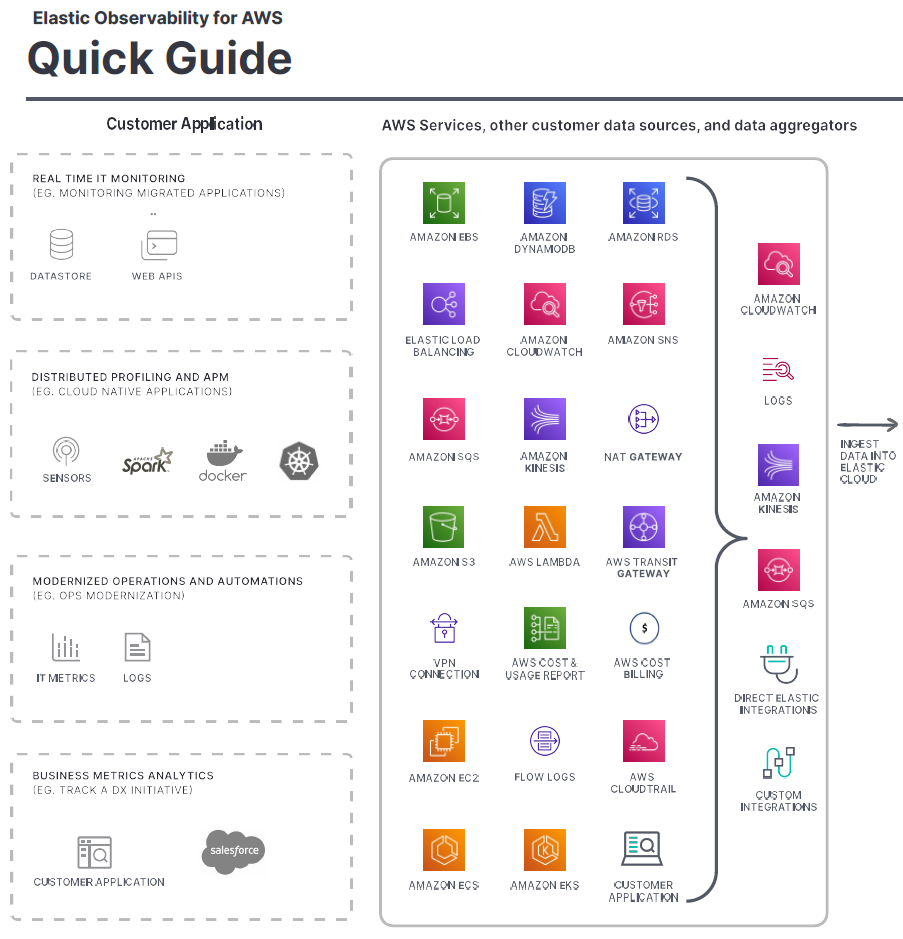
React faster and resolve problems before they impact your users with unified monitoring of your AWS ecosystem and cloud-native workloads. Start a free trial of Elastic Observability for AWS today.

Proactive insights for preventing system failures before they happen.

How to turn overwhelming complexity into a strategic advantage.

Understanding observability: The key to modern digital success.


Let us know what you think about the article.
