Fraud, AML, cyber and identity
The case for a composable architecture
The case for a composable architecture
Synthetic identities cross both fraud and AML with Mule accounts signalling money laundering risk, Bot traffic indicating a cyber compromise, and payment abuse blends fraud and customer-behaviour manipulation.
Yet most institutions address each discipline with separate tools, processes and data repositories. This fragmentation slows response, obscures connections and increases cost.
This is where a composable architecture provides three major advantages:
All risk and fraud functions work from a unified data layer. An AI data lake enables ingestion of fraud signals, AML events, identity data, sanctions lists, cyber telemetry and behavioural patterns into one searchable environment. This eliminates redundant ingestion pipelines and improves cross-discipline collaboration.
Teams can run their own models, workflows and rules without interfering with each other. Fraud teams investigate mule networks, AML teams analyse entity risk, and Cyber investigates account takeover attempts. Yet all teams draw from, and contribute to, the same real-time data environment.
Fraud threats evolve faster than technology procurement cycles. A composable architecture allows teams to add new use cases, integrate new datasets, or adopt new detection methods without ripping out core systems. This dramatically reduces long-term cost and accelerates response to emerging threats like deepfake-enabled identity fraud or AI-driven social engineering.
Cyber defends the perimeter. Fraud hides inside it. Architecture must support both.
Composable architectures also support regulatory expectations. Supervisors increasingly expect institutions to demonstrate unified risk-view capabilities across fraud and financial crime. Siloed systems make this difficult. Unified architectures make it natural.
Those adopting unified, flexible systems see faster case resolution, fewer false positives, better threat clustering, and stronger cross-team insight.
Fraud may be the entry point, but composability is the foundation for long-term resilience across the entire financial-crime landscape.
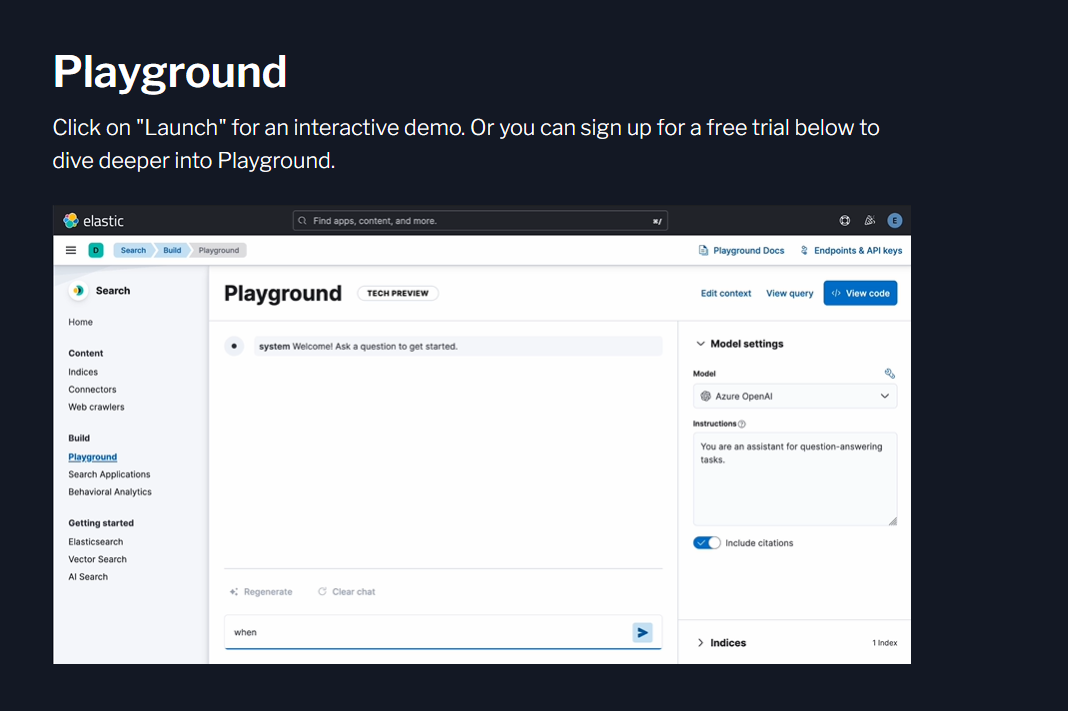
Test the latest AI search capabilities with AI Playground, now in Elasticsearch.
Ingest your own data or use our sample data to explore how to build RAG systems, test different LLMs from various providers like OpenAI, Amazon Bedrock, Anthropic and more.

How slow ingestion creates speed traps and blind spots.

Why better models don’t matter until the data problem is fixed.

Why incidents cost up to 20× more than their value.

Checklist for leaders in fraud, risk & financial crime.

What to collect, how to structure it, and how to make it usable.

How to modernise a legacy fraud stack without disruption.

Quantified benefits from modern fraud stacks.

How high-growth banks and PSPs reduce operational drag.

How search-led AI changes fraud detection.

Why enrichment, correlation and context change everything.

What a unified fraud data hub looks like.

Let us know what you think about the article.